TurboQuant and Vector Quantization: From Shannon to KV Cache Compression
Google Research recently published a blog post titled TurboQuant: Redefining AI efficiency with extreme compression. It describes a set of three algorithms, QJL, PolarQuant, and TurboQuant, that together achieve 3-bit KV cache compression with zero accuracy loss. At 4 bits, TurboQuant shows up to 8x speedup in computing the attention scores (the dot products between queries and keys) over the 32-bit baseline. TurboQuant is being presented at ICLR 2026.
The blog presents TurboQuant as one method, but it is really a stack of three papers: QJL (June 2024) provides the zero-overhead 1-bit correction, PolarQuant (February 2025) provides the polar coordinate transformation for KV caches, and TurboQuant (April 2025) unifies them with provable rate-distortion guarantees. Reading the blog without knowing this makes it harder to understand which piece does what.
I wanted to understand what the blog was actually proposing, and this post covers my learning journey. It is also meant as a guide for anyone who lacks the prerequisites to follow the blog completely: why KV cache compression matters, how existing quantization methods work, what Shannon’s rate-distortion theory says about the limits of compression, and how TurboQuant’s approach (random rotation + polar coordinates + 1-bit JL correction) fits together.
Why KV Cache Is the Bottleneck
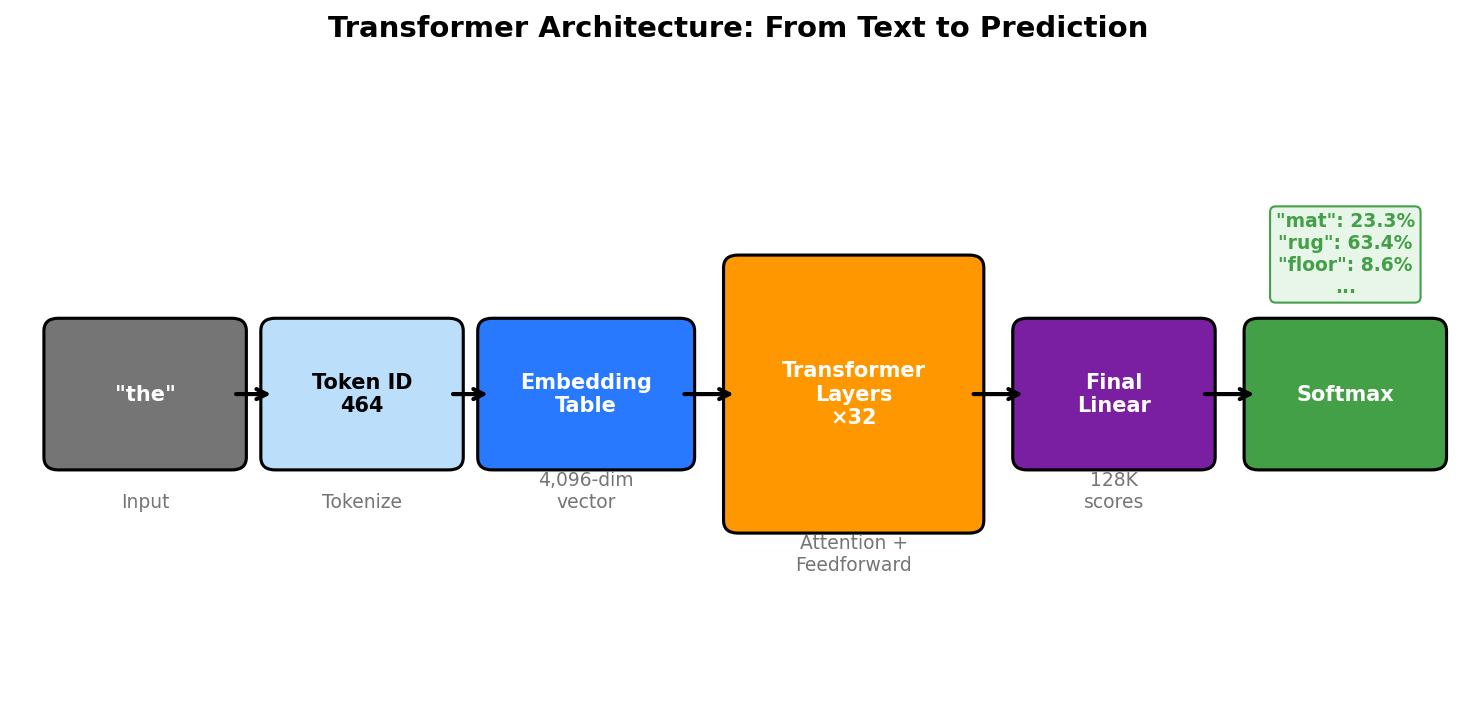
Tokens and Embeddings
Large language models generate text one token at a time. A token is roughly a word or a piece of a word. “cat” is one token. “understanding” might get split into “under” and “standing” as two tokens. The model’s vocabulary is a fixed list of these tokens, typically 32,000 to 128,000 entries.
Internally, the model does not work with words as text. It converts each token into a list of numbers called an embedding. This is a vector, a point in a high-dimensional space. For example, the token “cat” might become a vector of 4096 numbers:
"cat" → [0.12, -0.34, 0.56, 0.01, ..., -0.23] (4096 numbers)
Why 4096? That is a design choice. It is the hidden dimension of the model, sometimes called d_model. Larger models use more dimensions. GPT-2 uses 768. Llama-3.1-8B uses 4096. Llama-3.1-70B uses 8192. More dimensions means the model can encode more nuance about each token, but it also means more memory and computation.
How does a word get its embedding values? Before training, every token’s embedding is just random numbers. “cat” might start as [0.52, -0.11, 0.87, …] and “dog” might start as [0.33, 0.76, -0.44, …], completely meaningless. During training, the model reads billions of sentences and gradually adjusts these numbers. Tokens that appear in similar contexts (like “cat” and “kitten”, which both appear near words like “pet”, “fur”, “purred”) get their embeddings pushed closer together. Tokens that appear in very different contexts (like “cat” and “spreadsheet”) get pushed apart. How exactly the model learns these relationships during training is outside the scope of this article. I may cover that in a subsequent post.
After training, the embedding values encode patterns the model learned. But no single dimension has a clean human-readable meaning like “dimension 7 measures how alive something is.” It is more like mixing paint: no individual drop of color means “sunset,” but the right combination of many colors produces it. The model spreads meaning across all 4096 dimensions in whatever combination helps it predict text best.
What is the relationship between dimensions and parameters? The embedding table is itself a big grid of learned numbers. If the model has a vocabulary of 128,000 tokens and each embedding has 4096 dimensions, the embedding table alone contains 128,000 × 4096 = roughly 524 million numbers. Each of these numbers is a parameter, a value the model learned during training. On top of the embedding table, the model has many weight matrices, which are grids of learned numbers that transform the embeddings as they pass through the model. I will explain what W_Q, W_K, W_V, feed-forward networks, and layers are in the sections below. For now, the point is that the model has many such matrices and they are all filled with learned parameters. Add everything up and you get 8 billion parameters for Llama-3.1-8B.
So the dimension (4096) determines the shape of each matrix. The parameter count (8 billion) is the total number of learned values across all matrices in the model. A larger dimension means each token gets a richer representation but also means every matrix in the model gets bigger, which is why larger models have more parameters.
The embedding values tend to be small numbers, roughly between -1 and 1. The embedding values are learned during training. They start as random numbers and get adjusted as the model trains. They end up in a range where the math works well for the operations that follow. The exact values do not mean anything to a human, but the model learns that tokens with similar meanings end up with similar vectors. “cat” and “kitten” will have vectors that point in roughly the same direction, while “cat” and “spreadsheet” will point in very different directions.
Attention: How the Model Looks Back
Large language models generate text one token at a time. To decide what the next token should be, the model needs to look at all the tokens that came before it. This “looking back” is called attention. The mechanism was introduced in the paper “Attention Is All You Need” (Vaswani et al., 2017), which is the foundation of every modern transformer model.
Imagine you are writing a sentence and you have gotten to “The cat sat on the ___”. To fill in the blank, you need to look back at what you already wrote. Some previous words matter more than others. “cat” and “sat” are more relevant to your next word than “the”. Attention is how the model does this: it assigns a relevance score to every previous token and then pulls information from the most relevant ones.
Query, Key, and Value
For each token, the model computes three vectors. These are called the query, the key, and the value. The names come from database terminology, and the analogy is useful.
Think of a library catalog system:
- You walk in with a query: “I want books about animals”
- Every book on the shelf has an index card, a key: “this book is about cats”, “this book is about tax law”, “this book is about dogs”
- You compare your query against each key and find the best matches
- Each book also has actual content, the value: the pages inside the book
- You read the content (values) of the books whose keys matched your query
In the model, it works the same way:
"The cat sat on the ___"
Current position creates a query: "what should come after 'the'?"
query = [0.4, 0.6, 0.3]
Each previous token has a key: "cat" key = [0.8, 0.3, 0.1]
"sat" key = [0.5, 0.7, 0.2]
...
Each previous token has a value: "cat" value = [0.1, 0.9, 0.4]
"sat" value = [0.3, 0.5, 0.8]
...
These are not real numbers. I am using 3 dimensions to keep the examples readable. In an actual model like Llama-3.1-8B, each of these vectors has 128 dimensions. I will explain where that number comes from shortly.
Where do Q, K, V come from? They are computed by multiplying the token’s embedding by three separate weight matrices. A weight matrix is just a grid of numbers that the model learned during training. It transforms the embedding into a different representation suited for a specific purpose.
token embedding = [0.12, -0.34, 0.56, ...] (4096 numbers)
query = embedding × W_Q (W_Q is a 4096 × 128 matrix of learned weights)
key = embedding × W_K (W_K is a 4096 × 128 matrix of learned weights)
value = embedding × W_V (W_V is a 4096 × 128 matrix of learned weights)
The multiplication squeezes the 4096-dimensional embedding down to 128 dimensions. Each weight matrix extracts different information from the embedding. W_Q extracts “what am I looking for?”, W_K extracts “what do I contain?”, and W_V extracts “what information do I carry?” The model learns these matrices during training. After training, they are fixed.
The Attention Calculation Step by Step
Say the model has generated “The cat sat on the” and is deciding the next token. Here is a worked example with 3 dimensions.
Step 1: Compare the query against every key using a dot product.
A dot product is a way to measure how similar two vectors are. You multiply corresponding elements and add them up. Two vectors pointing in the same direction give a high dot product. Two vectors pointing in different directions give a low one.
Query for next token: [0.4, 0.6, 0.3]
query · "The" key: 0.4×0.2 + 0.6×0.1 + 0.3×0.4 = 0.26
query · "cat" key: 0.4×0.8 + 0.6×0.3 + 0.3×0.1 = 0.53
query · "sat" key: 0.4×0.5 + 0.6×0.7 + 0.3×0.2 = 0.68
query · "on" key: 0.4×0.1 + 0.6×0.9 + 0.3×0.4 = 0.70
query · "the" key: 0.4×0.3 + 0.6×0.1 + 0.3×0.5 = 0.33
“on” (0.70) and “sat” (0.68) score highest. “The” (0.26) scores lowest. This means the model considers “on” and “sat” most relevant for predicting what comes next.
Step 2: Convert scores to probabilities using softmax.
The raw dot products are just numbers. The model normalizes them into probabilities that add up to 1 using a function called softmax (it exaggerates the differences and makes them sum to 1).
Raw scores: [0.26, 0.53, 0.68, 0.70, 0.33]
After softmax: [0.11, 0.18, 0.21, 0.22, 0.13] (these add up to ~1.0)
The cat sat on the
Step 3: Use the probabilities to take a weighted average of the values.
Now the model multiplies each token’s value vector by its attention probability and adds them all up. Tokens with higher attention scores contribute more.
Output = 0.11 × value("The") + 0.18 × value("cat") + 0.21 × value("sat")
+ 0.22 × value("on") + 0.13 × value("the")
= 0.11 × [0.7, 0.3, 0.1] + 0.18 × [0.1, 0.9, 0.4] + 0.21 × [0.3, 0.5, 0.8]
+ 0.22 × [0.6, 0.2, 0.7] + 0.13 × [0.8, 0.4, 0.2]
= [0.44, 0.44, 0.49]
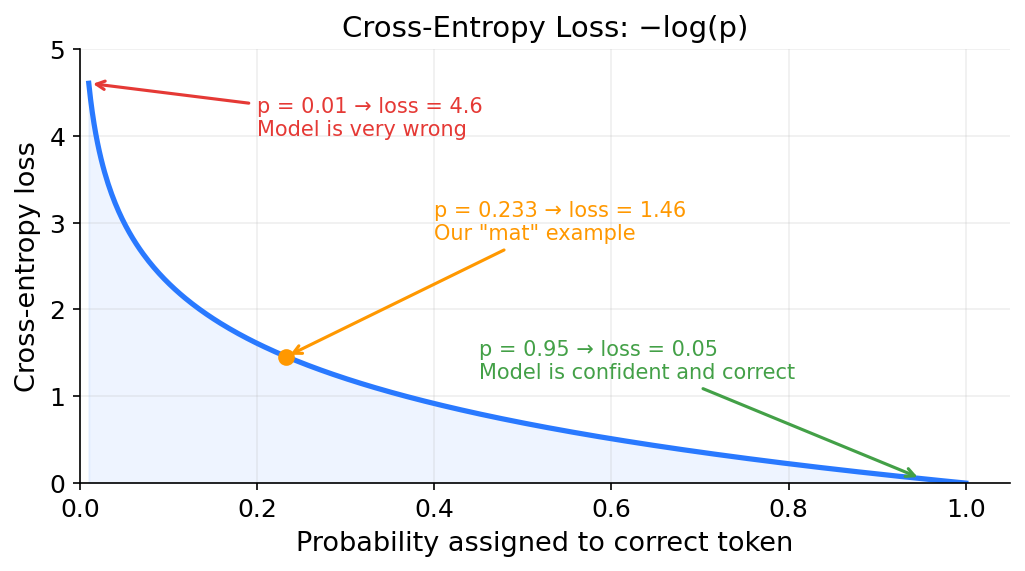
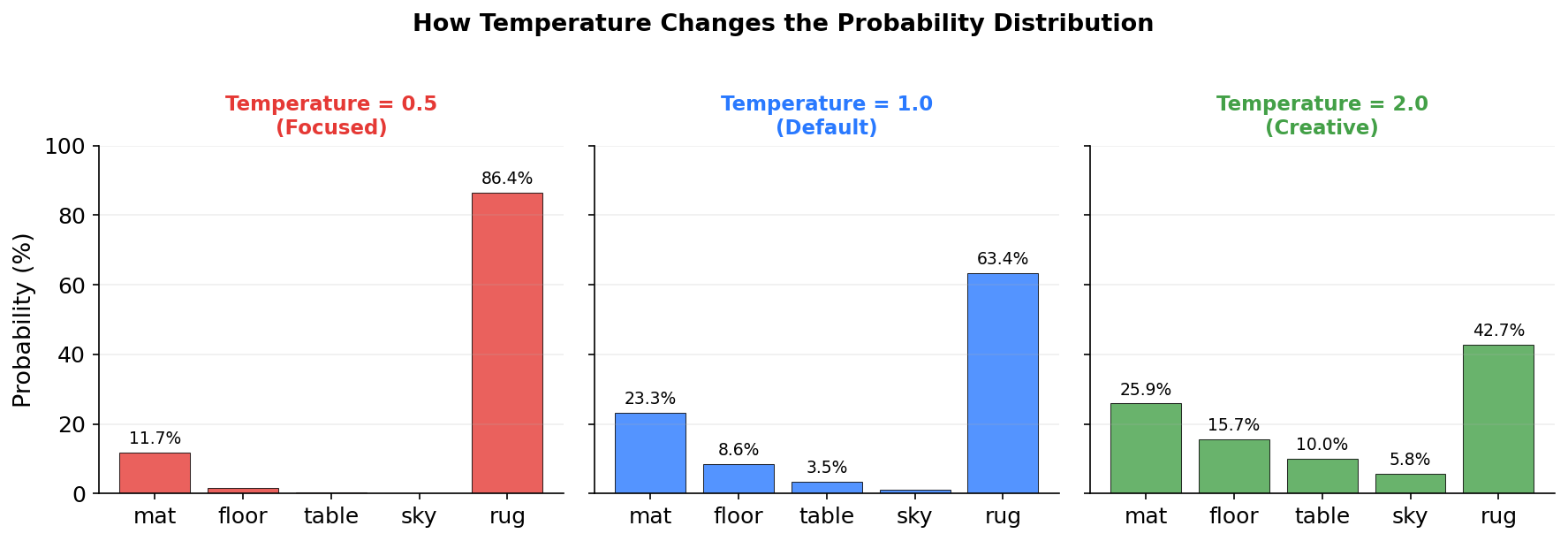
This output vector is a blend of information from all previous tokens, weighted by relevance. The model feeds this into further layers to predict the next token (probably “mat” or “floor”).
One might wonder why we need both keys and values instead of just one vector per token. The reason is that matching and carrying information are different jobs. Consider a search engine: you search by keywords (keys) but what you read is the page content (values). If the key and the value were the same thing, the model would be forced to use the same representation for “is this token relevant?” and “what information does this token contribute?”, which is a much harder problem.
Attention Heads: Why Multiple Perspectives Help
I said that each query/key/value vector is 128 dimensions while the embedding is 4096. This is because the model does not run attention once. It runs it 32 times in parallel, each time with a different set of weight matrices. Each of these parallel runs is called an attention head.
Why? Because different words matter for different reasons. Consider “The cat that I adopted from the shelter last week sat on the ___”:
- One head might focus on the subject-verb relationship: “cat” … “sat” → what did the cat sit on?
- Another head might focus on recency: “week” → is the time reference relevant?
- Another might track the article-noun pattern: “the ___” → expects a noun
Each head gets its own 128-dimensional slice of the 4096-dimensional space:
Head 1: dims 0-127 → learns to track subject-verb patterns
Head 2: dims 128-255 → learns to track positional relationships
Head 3: dims 256-383 → learns to track adjective-noun patterns
...
Head 32: dims 3968-4095 → learns something else
Total: 32 heads × 128 dims = 4096 dims
(The labels like “subject-verb patterns” are just illustrative. The model learns what each head specializes in during training, and the actual patterns are usually more abstract than human-readable categories.)
Each head independently computes its own query, key, and value, runs the attention calculation, and produces its own 128-dimensional output. The 32 outputs are concatenated back into a 4096-dimensional vector. This is the mechanism described in the original transformer paper (Vaswani et al., 2017, Section 3.2.2).
Grouped Query Attention: a memory optimization. In the original transformer (Vaswani et al., 2017), every head has its own query, key, and value matrices. With 32 heads, that means 32 sets of keys and 32 sets of values stored in the cache for every token. Each key and value is 128 dimensions, so for one token at one layer, the KV cache stores 32 × 128 × 2 (keys + values) = 8,192 numbers.
Llama-3.1-8B uses a technique called Grouped Query Attention (GQA), introduced by Ainslie et al. (2023). The idea is that the 32 query heads do not all need their own private key-value pair. Instead, groups of 4 query heads share the same key and value.
This might seem wrong at first. If one query head focuses on syntax and another on topic, how can they share the same key? The key for the token “cat” is the same 128 numbers regardless of which query head is looking at it. But different query heads extract different information from the same key.
An analogy: think of a person’s resume. One interviewer is hiring for programming skills and reads the resume focusing on the technical experience section. Another interviewer is hiring for leadership and reads the same resume focusing on management experience. The resume is the same document (the shared key), but each interviewer (query head) picks up on different parts of it because they are looking for different things.
Same key vector for token "cat": [0.8, 0.3, 0.1, 0.7, 0.2, ...]
↑ ↑
dims 0-63 might encode dims 64-127 might encode
syntactic role semantic meaning
Query head A (tracking syntax):
query_A · key = focuses on dims 0-63 → high score if "cat" is a subject
Query head B (tracking meaning):
query_B · key = focuses on dims 64-127 → high score if "cat" is an animal
Same key, different scores, because the queries emphasize different dimensions.
In practice, the split is not as clean as “first half = syntax, second half = meaning.” The 128 dimensions encode many overlapping aspects simultaneously, and each query head learns during training which dimensions to pay attention to. The empirical result from the GQA paper is that sharing keys and values across 4 query heads causes almost no quality loss. 128 dimensions is rich enough that multiple query heads can each find what they need from the same key.
Original (32 query heads, 32 KV heads):
Query head 1 → KV head 1
Query head 2 → KV head 2
...
Query head 32 → KV head 32
KV cache per token per layer: 32 keys + 32 values = 64 vectors
Grouped Query Attention (32 query heads, 8 KV heads):
Query heads 1-4 → share KV head 1
Query heads 5-8 → share KV head 2
...
Query heads 29-32 → share KV head 8
KV cache per token per layer: 8 keys + 8 values = 16 vectors
Why the Cache Grows and Why It Hurts
When the model generates “mat” as the next token, it computes a new key and value for “mat” and appends them to the cache. Now there are 6 key-value pairs stored. For the token after “mat”, the model will compare against all 6. The cache keeps growing.
But the attention calculation I described above is not the whole story. The model does not run attention once and produce the output. It runs the token through a stack of identical processing blocks called layers, one after another. Each layer takes the output of the previous layer, runs its own attention (with its own separate weight matrices and its own separate attention heads), and then applies a feed-forward network to further transform the result.
Think of it like an assembly line. The first layer might pick up on surface-level patterns (“the” is usually followed by a noun). The second layer builds on that (“the cat” is a noun phrase that is the subject of the sentence). By layer 10 or 15, the model is working with abstract representations of meaning. By the final layer, it has enough context to predict the next token.
Llama-3.1-8B has 32 of these layers. The number 32 is a design choice made by Meta when they built the model. There is no universal rule that says “use 32 layers.” Smaller models use fewer layers (GPT-2 Small has 12 layers), larger models use more (Llama-3.1-70B has 80 layers). More layers means the model can learn more complex patterns, but it also means more computation and more memory. The specific numbers (32 layers, 32 query heads, 8 KV heads, 128 dimensions per head) are all choices that Meta made to balance quality against cost for an 8-billion-parameter model.
Each layer has its own complete set of attention heads with its own weight matrices. The keys and values produced by layer 1 are completely separate from those produced by layer 2. To see the scale, here is what happens when a single token “cat” passes through the model:
Token "cat" passes through 32 layers:
Layer 1: 32 query heads (128 dims each), 8 KV heads (128 dims each)
→ stores 8 key vectors + 8 value vectors in cache
Layer 2: 32 query heads (128 dims each), 8 KV heads (128 dims each)
→ stores 8 key vectors + 8 value vectors in cache
...
Layer 32: 32 query heads (128 dims each), 8 KV heads (128 dims each)
→ stores 8 key vectors + 8 value vectors in cache
Total KV cache for one token:
32 layers × 8 KV heads × 128 dims × 2 (keys + values)
= 32 × 8 × 128 × 2
= 65,536 numbers stored per token
That is 65,536 numbers stored for a single token. For a 128K context window (131,072 tokens), multiply that out and you get the billions of numbers that make up the KV cache.
The memory cost scales as:
KV cache memory = 2 * num_layers * num_heads * head_dim * seq_len * bytes_per_value
2 → one set for keys, one for values
32 → layers
8 → KV heads per layer
128 → dimensions per head
131072 → sequence length (128K tokens)
2 → bytes per value (FP16 = 16 bits = 2 bytes)
For Llama-3.1-8B with a 128K context window:
2 * 32 * 8 * 128 * 131072 * 2 bytes = ~16 GB
To put that in perspective, the model weights (all the learned parameters we discussed earlier, the embedding table, W_Q, W_K, W_V matrices, feed-forward networks across all 32 layers) are a fixed cost. The model has 8 billion parameters. Each parameter is stored in FP16 (2 bytes), so the model size is:
Model size = 8,000,000,000 × 2 bytes = 16 GB (fixed, does not change)
The KV cache, on the other hand, depends on how long the conversation is:
Short conversation (1K tokens):
2 × 32 × 8 × 128 × 1,024 × 2 bytes = ~128 MB (small)
Medium conversation (16K tokens):
2 × 32 × 8 × 128 × 16,384 × 2 bytes = ~2 GB (noticeable)
Maximum context (128K tokens):
2 × 32 × 8 × 128 × 131,072 × 2 bytes = ~16 GB (as large as the model itself)
For a short chat, the KV cache is tiny compared to the model. But as the conversation gets longer, the KV cache grows while the model stays the same size. At maximum context length, they are roughly equal.
The real problem appears in batched serving, where you serve multiple users at the same time. The model weights are loaded once and shared across all users. But each user gets their own separate KV cache because each user has a different conversation. If you are serving 8 users with long contexts simultaneously:
Model weights: 16 GB (shared, loaded once)
KV caches: 8 users × 16 GB = 128 GB (separate per user)
Total: 144 GB
The KV cache is 8x larger than the model itself.
A smaller model has a smaller fixed cost but the KV cache scaling problem is the same. For Llama-3.1-70B (70 billion parameters, 80 layers, more heads), the model is larger but the KV cache also grows proportionally, and batched serving makes it worse.
When you see “200K context window” in Claude or “1M context” in Gemini, that number is the maximum number of tokens the model can look back at. It is the maximum length of the KV cache. The longer the context window, the more memory the KV cache consumes. This is why long-context models are expensive to serve and why there is so much interest in compressing the KV cache.
Quantizing the KV cache from FP16 (16 bits) down to 3 or 4 bits per value shrinks it by 4-5x. For the 8-user example above, that takes the KV cache from 128 GB down to around 25-30 GB, which is the difference between fitting on a single GPU and needing a whole cluster of them.
The Theory: How Much Can You Compress?
Shannon’s Rate-Distortion Function
Before looking at any specific algorithm, it helps to know the theoretical limit. How much can you compress something before the quality becomes unacceptable?
This is exactly the question Claude Shannon answered in his 1948 paper “A Mathematical Theory of Communication.” He introduced the rate-distortion function, which tells you the minimum number of bits per sample needed to keep the reconstruction error below some threshold.
To understand the formula, I need to explain a few terms.
Distortion is the error introduced by compression. If you store the number 0.87 but after compression and decompression you get back 0.85, the error is 0.02. The standard way to measure this across many values is mean-squared error (MSE): you take the difference between each original and reconstructed value, square it, and average over all values. Squaring makes large errors count more than small ones.
Variance (σ²) measures how spread out the data is. If all your values are close to the average, variance is low and the data is easier to compress (it is more predictable). If the values are spread all over the place, variance is high and you need more bits to capture the differences. The KV cache values in a transformer have some variance that depends on the model and the input.
Neural network activations are the intermediate values that flow through the model as it processes input. When a token passes through a layer, the attention mechanism and the feed-forward network produce output values at each step. These intermediate outputs are the activations. The key and value vectors in the KV cache are activations: they are computed on the fly as the model processes each token, not learned during training like the weights.
Gaussian source means the data follows a bell curve distribution. Most values cluster around the average, and values further from the average become increasingly rare.
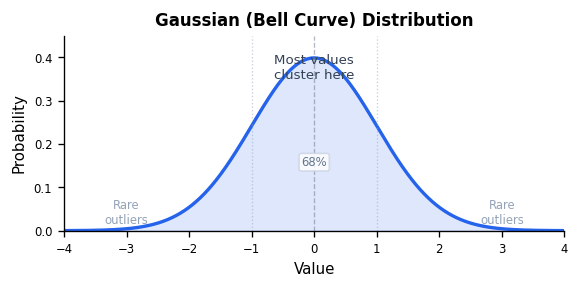
This is the most common assumption in information theory because many natural processes produce data that is approximately Gaussian. Neural network activations roughly follow this pattern too: most KV cache values are moderate, clustered around zero, with values further from zero becoming less common.
The assumption is not perfect though. In a true Gaussian distribution, extreme values (say, 100x larger than the average) are so rare that they essentially never happen. In real neural network activations, extreme values show up more often than a Gaussian would predict. These are the “outliers” we will see later when discussing SmoothQuant and KIVI. For example, in a layer’s activations, 99% of the values might be between -1 and 1, but a handful of channels consistently produce values of 50 or 100. This is what “heavier tails” means: the tails of the distribution (the extreme ends) have more probability mass than a Gaussian predicts.
Gaussian prediction: value of 50 should appear 1 in 10^500 times (never)
Real activations: value of 50 appears in a few channels regularly
Gaussian Real activations
╱╲ ╱╲
╱ ╲ ╱ ╲
╱ ╲ ╱ ╲
╱ ╲ ╱ ╲____
╱ ╲___ ╱ ╲___
───────────────── ──────────────────────
tails drop fast tails drop slower (heavier)
Despite this mismatch, the Gaussian assumption is close enough for the theoretical analysis. Shannon’s rate-distortion formula gives a useful lower bound on how much you can compress, even if the real distribution is not exactly Gaussian. The practical quantization methods covered later in this article are designed to handle the outliers that the theory does not account for.
With those definitions, Shannon’s rate-distortion function for a Gaussian source is:
R(D) = (1/2) * log₂(σ² / D)
R(D) = minimum bits per value needed
σ² = variance of the data (how spread out the values are)
D = maximum acceptable mean-squared error
log₂ = logarithm base 2 (because we are counting bits)
A concrete example: suppose the KV cache values have a variance of 1.0 (meaning the values are spread out with a standard deviation of 1, so most values fall between -1 and 1) and you can tolerate a mean-squared error of 0.01.
R(0.01) = (1/2) * log₂(1.0 / 0.01)
= (1/2) * log₂(100)
= (1/2) * 6.64
= 3.32 bits per value
This says no algorithm can represent these values with less than 3.32 bits per value while keeping the MSE at or below 0.01. It does not matter how clever your algorithm is. This is a hard mathematical floor. No compression algorithm can do better than this regardless of how clever it is.
If you want less distortion (say D = 0.001), you need more bits:
R(0.001) = (1/2) * log₂(1.0 / 0.001)
= (1/2) * log₂(1000)
= (1/2) * 9.97
= 4.98 bits per value
And if you can tolerate more distortion (D = 0.1), you need fewer bits:
R(0.1) = (1/2) * log₂(1.0 / 0.1)
= (1/2) * log₂(10)
= (1/2) * 3.32
= 1.66 bits per value
This is the fundamental tradeoff: fewer bits means more distortion, and Shannon tells you exactly where the floor is.
TurboQuant proves that for a given bit budget, its distortion is at most 2.7 times the minimum possible distortion from Shannon’s formula. To put that concretely: if Shannon’s bound says the minimum achievable MSE at 3 bits is 0.01, TurboQuant guarantees its MSE will be at most 0.027.
Most quantization algorithms in this space have no proven worst-case guarantee. They are tuned empirically and could degrade unpredictably on different data. TurboQuant’s bound means the distortion is predictable and bounded no matter what input it sees.
Why Quantize at All?
The KV cache stores values in FP16, which uses 16 bits per number. That gives very high precision but consumes a lot of memory, as we saw above. Quantization reduces the number of bits used to represent each value.
What do we gain? Memory savings. Storing each value in 4 bits instead of 16 bits cuts memory by 4x. For the 8-user serving example, that takes the KV cache from 128 GB down to 32 GB.
What do we lose? Precision. With 16 bits you can represent 65,536 distinct values. With 4 bits you only get 16. Every original value has to be rounded to one of those 16 levels, and that rounding introduces error. The question is how to do this rounding in a way that minimizes the error for a given bit budget.
There are two main approaches: scalar quantization and vector quantization.
Scalar Quantization
The simplest approach. You take each number independently and snap it to the nearest value in a fixed set of levels. If you have 4 bits, you get 2⁴ = 16 levels spread across the range of your data.
Scalar quantization (4-bit, 16 levels):
Fixed set of 16 levels (evenly spaced from 0.0 to 1.0):
[0.0, 0.07, 0.13, 0.20, 0.27, 0.33, 0.40, 0.47,
0.53, 0.60, 0.67, 0.73, 0.80, 0.87, 0.93, 1.00]
Each original value gets mapped to the closest level in this set:
0.31 → 0.33 (closest level)
0.87 → 0.87 (exact match)
0.52 → 0.53 (closest level)
0.14 → 0.13 (closest level)
Original values: [0.31, 0.87, 0.52, 0.14]
Quantized values: [0.33, 0.87, 0.53, 0.13]
Each value is stored as a 4-bit index (0-15) into the set of 16 levels.
4 values × 4 bits = 16 bits total.
Original was 4 values × 16 bits = 64 bits. That is a 4x compression.
Scalar quantization is simple, fast, and has good hardware support. The downside is that it treats every number in isolation. It does not know or care that the numbers might be related to each other.
Vector Quantization
Instead of quantizing each number on its own, vector quantization treats a group of numbers as a single point and maps the whole group to the nearest entry in a precomputed table. This table is called a codebook, and each entry in it is called a codeword. The codebook is like a palette of allowed colors: every input vector gets matched to the closest color in the palette.
Vector quantization (2D, 4 codewords):
Original vector: (0.31, 0.87) ← this is a point in 2D space
Codebook (our palette of 4 allowed points):
c0 = (0.25, 0.75)
c1 = (0.75, 0.75)
c2 = (0.25, 0.25)
c3 = (0.75, 0.25)
Nearest codeword: c0 = (0.25, 0.75)
Encoded as: index 0
We have 4 codewords, so we need 2 bits to pick one of them
(00 = c0, 01 = c1, 10 = c2, 11 = c3). Those 2 bits encode the
entire pair of numbers at once, so on average that is 1 bit per number.
But this is not the full cost. The codebook itself also takes up
memory. In this example, the codebook has 4 codewords, each
containing 2 floats at 16 bits each, so the codebook costs
4 × 2 × 16 = 128 bits. That is real overhead. The key difference
is that the codebook is stored once and shared across all vectors.
If you are quantizing 10,000 vectors, the codebook cost is 128 bits
shared over 10,000 vectors, which adds about 0.01 bits per vector.
The more vectors you quantize, the more negligible this becomes.
So the true per-vector cost of VQ is: 2 bits (index) + a tiny
amortized share of the codebook.
The advantage of vector quantization is that it can adapt to the shape of the data. Imagine plotting thousands of 2D data points on a scatter chart. They will not be spread evenly across the entire square. They will cluster in certain regions. Scalar quantization ignores these clusters and uses a uniform grid everywhere, wasting levels on empty regions. Vector quantization can place its codewords right where the data actually is, putting more codewords in dense regions and fewer in empty ones.
To put it concretely: if your KV cache values tend to come in patterns (say, when dimension 3 is high, dimension 7 is usually also high), scalar quantization ignores that pattern and quantizes both dimensions independently. Vector quantization can learn a codeword that captures the pattern directly, representing both dimensions together with fewer bits and less error.
The tradeoff is complexity. Vector quantization needs a codebook, which has to be built from the data ahead of time using algorithms like Lloyd’s (covered in the next section). The encoding step requires finding the nearest codeword in the codebook, which is more expensive than just rounding a number. And decoding requires a table lookup instead of simple arithmetic. But at low bit rates (2-4 bits per value), the quality advantage over scalar quantization is real and grows as you compress more aggressively. This is the regime TurboQuant operates in.
Lloyd’s Algorithm (1957)
Lloyd’s algorithm is the classic method for building VQ codebooks. It is essentially k-means clustering applied to the quantization problem:
- Start with an initial set of codewords
- Assign each data point to the nearest codeword
- Update each codeword to be the centroid of its assigned points
- Repeat until convergence
One practical problem with Lloyd’s algorithm is: how do you pick the initial codewords? If you start with bad initial positions, the algorithm can converge to a poor solution. The Linde-Buzo-Gray (LBG) algorithm from 1980 solves this by starting with just one codeword (the average of all data points) and then repeatedly splitting each codeword into two, running Lloyd’s algorithm after each split. You go from 1 codeword to 2, then 4, then 8, and so on until you reach the desired codebook size. Each split doubles the codebook and each round of Lloyd’s refines the positions. This gives a more reliable initialization than picking random starting points.
The deeper problem with Lloyd’s algorithm for KV cache compression is that it needs all the data upfront. You have to pass over all your data points multiple times (steps 2-4 repeat until convergence) to build the codebook. This works fine for weight quantization, where the weights are fixed and you can spend as long as you want building the codebook offline.
But the KV cache is not fixed. It grows in real time. During autoregressive generation, which is how language models produce text, the model generates one token at a time. It produces “The”, then uses that to produce “cat”, then uses “The cat” to produce “sat”, and so on. Each new token adds a new key-value pair to the cache. You cannot pause generation, collect all the key-value vectors, run Lloyd’s algorithm to build a codebook, and then start quantizing. The vectors arrive one at a time and need to be compressed immediately.
You need an online algorithm, one that can quantize each vector as it arrives without knowing what vectors will come next. This is the specific constraint that TurboQuant addresses.
The Landscape: How LLMs Are Quantized Today
Weight Quantization
Weight quantization compresses the model’s learned parameters, the W_Q, W_K, W_V matrices and feed-forward network weights we saw earlier. A model like Llama-3.1-8B has about 8 billion of these weight values. At full precision (FP16, 16 bits each), that is roughly 16 GB. At INT4 (4-bit integers, where each weight is stored as one of 16 possible levels), it drops to about 4 GB.
The key property of weights is that they are static. Once training is done, the weights do not change. This means you can spend hours analyzing the weights to figure out the best way to quantize them. You only pay this cost once, and then you serve the quantized model forever. This offline analysis is called post-training quantization (PTQ).
The three most widely used methods are:
GPTQ (Frantar et al., October 2022) tries to figure out which weights matter most. Not all weights affect the model’s output equally. Some weights, if rounded slightly wrong, cause large errors in the output. Others can be rounded aggressively with little impact. GPTQ measures this sensitivity using the Hessian, which is a mathematical tool that tells you how much the model’s loss function changes when you perturb each weight. Weights with high Hessian values are quantized more carefully. GPTQ processes one layer at a time and is the standard method for compressing models to INT4 (4 bits per weight).
AWQ (Lin et al., June 2023) approaches the same problem from a different angle. Instead of looking at the weights directly, it looks at the activations. Activations are the intermediate values that flow through the model when it processes input. When a token’s embedding gets multiplied by a weight matrix, the result is an activation. When that result passes through an attention layer and then a feed-forward layer, each step produces more activations. The model uses these activations during inference, which is the process of running the model to generate output (as opposed to training, where the model is learning its weights).
AWQ observes that a small fraction of activation channels carry much larger values than the rest. A channel is one dimension of the activation vector. If a 4096-dimensional activation vector consistently has a value of 50.0 in dimension 42 but values below 1.0 in dimension 43, then dimension 42 is an outlier channel. The weights connected to channel 42 are more important because errors in those weights get amplified by the large activation value. AWQ protects these critical weights by scaling them up before quantization so they get finer-grained levels. This improves on GPTQ at INT4.
SmoothQuant (Xiao et al., November 2022) targets INT8 (8 bits per value) for both weights and activations. Quantizing activations is harder than quantizing weights because activations have outliers.
A concrete example shows why outliers are a problem. Suppose a layer produces these activation values across 4 channels:
Activations: [0.5, 0.3, 0.1, 100.0]
↑
outlier channel
To quantize with INT8 (256 levels), you need to set the quantization range to cover the full spread. The range must go from 0 to 100 to include the outlier. That means each of the 256 levels covers a step of 100/256 ≈ 0.39.
Quantization range: 0 to 100, step size = 0.39
0.5 → rounds to 0.39 (error: 0.11)
0.3 → rounds to 0.39 (error: 0.09)
0.1 → rounds to 0.00 (error: 0.10)
100 → rounds to 100.0 (error: 0.00)
The three small values (0.5, 0.3, 0.1) are all crammed into the first
two levels. They become nearly indistinguishable. Most of the 256 levels
are wasted on the range 1-100 where there is only one value.
SmoothQuant fixes this by redistributing the difficulty between the activation and the weight. The idea is that in a transformer, the output of a layer is always activation × weight. If you divide the activation by some factor s and multiply the weight by the same factor s, the product stays exactly the same:
Original: activation × weight = result
SmoothQuant: (activation / s) × (weight × s) = same result
For the outlier channel, you pick a large scaling factor. For the normal channels, you pick a small one:
Before SmoothQuant:
Activations: [0.5, 0.3, 0.1, 100.0]
Weights: [2.0, 1.5, 3.0, 0.5]
Scaling factors per channel: [1, 1, 1, 50]
(large factor for the outlier channel)
After SmoothQuant:
Activations: [0.5/1, 0.3/1, 0.1/1, 100/50] = [0.5, 0.3, 0.1, 2.0]
Weights: [2.0×1, 1.5×1, 3.0×1, 0.5×50] = [2.0, 1.5, 3.0, 25.0]
The activation is now smooth: all values between 0.1 and 2.0.
The weight got rougher: 25.0 in the last channel.
But the product for each channel is unchanged:
0.5×2.0 = 1.0 (same as before: 0.5×2.0)
0.3×1.5 = 0.45 (same as before: 0.3×1.5)
0.1×3.0 = 0.30 (same as before: 0.1×3.0)
2.0×25.0 = 50.0 (same as before: 100×0.5)
Now the activation range is 0.1 to 2.0 instead of 0.1 to 100. Quantizing this with 256 levels gives a step size of about 0.008, which is precise enough to distinguish 0.1, 0.3, and 0.5 from each other. The weight got rougher, but weights are static and can be quantized more carefully using methods like GPTQ.
All three are scalar methods. They quantize each weight or activation value independently. They all have mature support on NVIDIA GPUs through CUDA (NVIDIA’s programming framework for running computation on GPUs) and are widely deployed in production serving of models like Llama, Mistral, and others.
KV Cache Quantization
The KV cache is a different problem from weight quantization. Weights are fixed once training is done, so you can analyze them carefully offline. The KV cache is dynamic. It grows with every token the model generates, and the values have different statistical properties from weights.
KIVI (Liu et al., February 2024) proposes 2-bit quantization for the KV cache. Its key observation is that keys and values have different outlier patterns and should not be quantized the same way.
In the key vectors, the outliers tend to appear in the same channels across all tokens. No matter what token produced the key, channel 50 might always have a large value. This is a per-channel pattern.
In the value vectors, the outliers tend to appear in the same token across all channels. Token 200 might have large values in every channel while other tokens are mild. This is a per-token pattern.
Key outlier pattern (same channel, all tokens):
ch1 ch2 ch50 ch100
Token 1: 0.3 0.1 98.0 0.2
Token 2: 0.5 0.4 95.0 0.1
Token 3: 0.2 0.3 101.0 0.4
↑
channel 50 is always large
Value outlier pattern (same token, all channels):
ch1 ch2 ch50 ch100
Token 1: 0.3 0.1 0.5 0.2
Token 2: 0.5 0.4 0.3 0.1
Token 200: 85.0 72.0 91.0 88.0 ← this entire token is an outlier
Token 3: 0.2 0.3 0.4 0.4
KIVI uses this difference. For keys, it sets the quantization range per-channel: channel 50 gets its own min/max (say 90 to 105), while channel 1 gets a tighter range (0 to 1). This way the 4 levels of 2-bit quantization are spread appropriately for each channel. For values, it sets the range per-token: token 200 gets its own wide range while normal tokens get tight ranges.
This is what asymmetric quantization means here: keys and values are handled with different strategies that match their outlier patterns. The result is 2-bit precision with no fine-tuning needed.
KVQuant (Hooper et al., January 2024) pushes further, targeting sub-4-bit quantization to make 10-million-token context windows feasible. At that scale, even small per-value savings multiply into hundreds of gigabytes.
One technique KVQuant uses is non-uniform quantization levels. In the scalar quantization examples earlier, we spaced levels evenly across the range. But if most values cluster near zero with a few outliers far away, evenly spaced levels waste most of their resolution on empty space. Non-uniform quantization places levels closer together where values are common and further apart where they are rare.
Uniform levels (4-bit, 16 levels from -10 to 10):
|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|
-10 -5 0 5 10
Most values are between -1 and 1, but only 2 of 16 levels fall there.
Non-uniform levels (4-bit, 16 levels, clustered near zero):
|--|--|--|--|----|-------|------------|------------|-------|----|----|--|--|
-10 -2 -1 0 1 3 6 8 9 10
8 of 16 levels fall between -2 and 2, where most values actually are.
KVQuant computes where the data is dense by looking at the distribution of KV values across a calibration dataset (a set of representative inputs run through the model before deployment). The KV cache is dynamic during inference, but the statistical patterns of which ranges are dense tend to be consistent across inputs for a given model. KVQuant also applies a rotation to the key vectors before quantization to reduce outliers, similar in spirit to SmoothQuant’s approach of redistributing the difficulty.
GEAR (Kang et al., March 2024) takes a completely different approach. Instead of quantizing every value in the KV cache, it separates the cache into two parts. The first part is a low-rank approximation: a compressed version that captures the main patterns in the data using far fewer numbers, similar to how a blurry photo captures the general shapes but loses the fine details. The second part is a sparse residual: it stores only the entries where the low-rank approximation was far off (the outliers), at full precision. Everything else is discarded. The idea is that most of the KV cache is predictable and compressible, and only a few entries need to be stored accurately.
All three are scalar approaches. They quantize or compress individual values in the KV cache, possibly with different strategies per channel or per token, but they do not treat groups of values as vectors.
The Google Blog’s Proposal: Three Algorithms
The Google Research blog post describes TurboQuant as combining two earlier algorithms from the same group: QJL and PolarQuant. Each solves a different piece of the KV cache compression problem. TurboQuant brings them together into a unified method.
QJL: 1-Bit Quantization with Zero Overhead
The first paper is QJL (Zandieh, Daliri, Han, June 2024), which stands for Quantized Johnson-Lindenstrauss.
To understand the problem QJL solves, consider what happens when you quantize a block of values. You reduce each value to a few bits, but you also need to store some bookkeeping information alongside the quantized data. Specifically, you need a scale factor (how wide is the range of values?) and a zero point (where does the range start?). Without these two numbers, the receiver cannot reconstruct the original values from the quantized bits.
Example: quantizing [0.12, 0.87, 0.53, 0.31] to 2 bits per value
Step 1: Find the range.
Min = 0.12, Max = 0.87
Step 2: Create 4 evenly spaced levels (2 bits = 2² = 4 possible levels).
Level 0 = 0.12
Level 1 = 0.37
Level 2 = 0.62
Level 3 = 0.87
Step 3: Map each original value to the nearest level.
0.12 → Level 0 (0.12) stored as bit code 00
0.87 → Level 3 (0.87) stored as bit code 11
0.53 → Level 2 (0.62) stored as bit code 10
0.31 → Level 1 (0.37) stored as bit code 01
Stored data: [00, 11, 10, 01]
That is 4 values × 2 bits each = 8 bits total for the data.
But to decode these bits back into numbers, you also need to know
the scale and zero point:
Scale factor: (0.87 - 0.12) / 3 = 0.25 (stored as FP16, 16 bits)
Zero point: 0.12 (stored as FP16, 16 bits)
To reconstruct: value = zero_point + bit_code × scale
00 → 0.12 + 0 × 0.25 = 0.12
11 → 0.12 + 3 × 0.25 = 0.87
10 → 0.12 + 2 × 0.25 = 0.62
01 → 0.12 + 1 × 0.25 = 0.37
Total storage: 8 bits (data) + 32 bits (scale + zero point) = 40 bits
Effective: 40 bits / 4 values = 10 bits per value, not 2.
For a small block, the metadata overhead can dominate. At low bit widths (1-2 bits per value), this overhead partly defeats the purpose of compressing in the first place.
QJL sidesteps this problem entirely. It uses a result from high-dimensional geometry called the Johnson-Lindenstrauss (JL) lemma. The idea behind JL is that if you take vectors in a high-dimensional space (say 4096 dimensions) and multiply them by a random matrix to project them down to fewer dimensions, the distances and angles between the vectors are approximately preserved. Two vectors that were similar before the projection will still be similar after it, and two vectors that were different will still be different.
QJL takes this one step further. After applying the random projection, it keeps only the sign of each resulting coordinate: positive becomes +1, negative becomes -1. That is 1 bit per coordinate. No scale factor, no zero point, nothing else to store. The entire representation is just a string of sign bits.
QJL compression of a key vector:
Original key: [0.31, -0.72, 0.15, -0.44, ...] (128 FP16 values = 2048 bits)
|
Multiply by random matrix R
|
Projected: [0.08, -0.23, 0.41, -0.15, ...]
|
Keep only the sign
|
Stored: [+1, -1, +1, -1, ...] (128 bits, no metadata)
But how do you compute attention with sign bits? Attention needs the dot product between a query and a key (as we saw earlier). QJL keeps the query at full precision and only compresses the cached keys. To estimate the dot product between a full-precision query and a 1-bit key, QJL uses a formula that multiplies the absolute value of each query coordinate by the sign of the corresponding key coordinate and averages the result.
The paper proves two things about this estimate. First, it is unbiased: on average, the estimate equals the true dot product. It does not systematically overestimate or underestimate. Second, the variance (how much the estimate fluctuates around the true value) decreases as you use more dimensions. Variance measures the spread of the estimate: low variance means the estimate is reliably close to the truth, high variance means it jumps around. With 128 dimensions, the estimate is reasonably stable.
For KV cache, this means keys can be stored at 1 bit per dimension with zero memory overhead from metadata. The tradeoff is that 1 bit is extreme compression and the estimate is noisier than higher-bit methods. That is where PolarQuant comes in.
PolarQuant: Polar Coordinates for Quantization
PolarQuant (Han, Kacham, Karbasi, Mirrokni, Zandieh, February 2025) takes a completely different approach. Instead of compressing the raw numbers directly, it first changes the way the vector is represented.
To understand this, consider two ways to describe a location. You can say “go 3 blocks East and 4 blocks North” or you can say “go 5 blocks at a 53-degree angle.” Both describe the same point, but they use different coordinate systems. The first is Cartesian coordinates (x, y), which is what we normally work with. The second is polar coordinates (radius, angle), which separates “how far” from “which direction.”
Cartesian: (3, 4) "3 East, 4 North"
Polar: (5, 53°) "5 blocks at 53 degrees"
The radius is the distance: √(3² + 4²) = √25 = 5
The angle is: arctan(4/3) ≈ 53°
PolarQuant converts KV cache vectors from Cartesian to polar coordinates before quantizing them. The insight is that in many models, the direction of a KV vector (which way it points in the high-dimensional space) carries more information than its magnitude (how long it is). Two tokens with similar meanings will have KV vectors pointing in similar directions, even if their magnitudes differ. By separating direction from magnitude, you can allocate more bits to the direction (which matters more) and fewer to the magnitude (which varies less).
The conversion works recursively, pairing up coordinates at each level:
Input: 4-dimensional vector [3, 4, 1, 2]
Step 1: Group into pairs: (3, 4) and (1, 2)
Step 2: Convert each pair from Cartesian to polar:
(3, 4) → radius = √(9+16) = 5.0, angle = arctan(4/3) = 53°
(1, 2) → radius = √(1+4) = 2.24, angle = arctan(2/1) = 63°
Step 3: Now we have two radii: (5.0, 2.24). Group them as a pair.
Step 4: Convert that pair to polar:
(5.0, 2.24) → radius = √(25+5) = 5.48, angle = arctan(2.24/5.0) = 24°
Result: one final radius (5.48) and three angles (53°, 63°, 24°)
The final radius is just the length of the original vector. The angles capture the direction. For a vector with d dimensions, you end up with 1 radius and d-1 angles.
The angles have a useful property: they always fall within a bounded range (0° to 360°, or equivalently 0 to 2π). This makes them easier to quantize than the original Cartesian coordinates, which can be any real number. When you know the range upfront, you can place your quantization levels evenly across it without worrying about outliers stretching the range.
Before the polar conversion, PolarQuant applies a preprocessing step: it multiplies the vector by a Hadamard matrix. A Hadamard matrix is a specific type of square matrix filled with +1 and -1 values, arranged so that the multiplication spreads the energy of the vector evenly across all coordinates. Without this step, a few coordinates might carry most of the information while the rest are near zero. That would waste quantization levels on the near-zero coordinates. After the Hadamard rotation, every coordinate carries a roughly equal share of the information, so quantization levels are used efficiently. This same trick appears in QuIP and QuIP#, two earlier vector quantization methods for LLM weights.
PolarQuant pipeline:
Input vector v (128 dimensions)
|
Multiply by Hadamard matrix (spreads energy evenly)
|
Rotated vector v' (all coordinates now carry similar energy)
|
Recursive polar conversion (pair, convert, pair, convert, ...)
|
1 radius + 127 angles
|
Quantize angles with optimal scalar quantizers
|
Store: quantized angles + radius
The paper shows that PolarQuant achieves near-lossless KV cache compression. On the “needle in a haystack” benchmark, which tests whether the model can find a specific piece of information buried in a very long context (a task that is extremely sensitive to KV cache quality), PolarQuant matches the uncompressed model.
TurboQuant: Putting It Together
TurboQuant (Zandieh, Daliri, Hadian, Mirrokni, April 2025) combines the ideas from QJL and PolarQuant into a single framework with provable guarantees on how much error it introduces. It is being presented at ICLR 2026.
The core problem TurboQuant solves is: how do you build a vector quantizer that works well without seeing the data ahead of time? Lloyd’s algorithm needs multiple passes over the data. PolarQuant’s polar conversion is data-oblivious but does not have provable optimality guarantees. TurboQuant achieves both: data-oblivious operation and provable near-optimality.
The algorithm has two stages.
Stage 1: Rotate and quantize
The first step is to multiply the input vector by a random orthogonal matrix. An orthogonal matrix is a square matrix with a special property: multiplying a vector by it rotates the vector in space without changing its length or any of the angles between vectors. Nothing is stretched or squashed, the vector just points in a new direction.
A simple 2D example makes this concrete. The matrix below is orthogonal (each row has length 1, and the two rows are perpendicular to each other):
Orthogonal matrix (a 45-degree rotation):
R = [ 0.71 -0.71 ] row 1: length = √(0.71² + 0.71²) = 1.0 ✓
[ 0.71 0.71 ] row 2: length = √(0.71² + 0.71²) = 1.0 ✓
row1 · row2 = 0.71×0.71 + (-0.71)×0.71 = 0 ✓ (perpendicular)
Multiplying:
R × [1.0, 0.0] = [0.71×1.0 + (-0.71)×0.0, 0.71×1.0 + 0.71×0.0]
= [0.71, 0.71]
Original: (1.0, 0.0) length = √(1² + 0²) = 1.0
Rotated: (0.71, 0.71) length = √(0.71² + 0.71²) = 1.0 (same length)
The vector was pointing along the x-axis, and the orthogonal matrix rotated it to point diagonally. The length stayed at 1.0.
This raises an important question: if we rotate the vector, do we lose the meaning encoded in it? The answer is no, and this comes from a core property of linear algebra. Orthogonal rotations preserve three things:
- Lengths of vectors (as shown above).
- Distances between any two vectors. If “cat” and “kitten” were close together before rotation, they are still exactly the same distance apart after rotation.
- Dot products between any two vectors. This is the critical one for attention. Recall that attention computes the dot product between query and key vectors to find which tokens are relevant. If
dot_product(query, key_A) > dot_product(query, key_B) before rotation, the exact same ordering holds after rotation. No attention scores change.
Before rotation:
query · key_A = 0.85 (token A is more relevant)
query · key_B = 0.32 (token B is less relevant)
After rotating ALL vectors by the same orthogonal matrix R:
(R × query) · (R × key_A) = 0.85 (same score, exactly)
(R × query) · (R × key_B) = 0.32 (same score, exactly)
The rotation changes the coordinate system, not the relationships between vectors. Think of it like rotating a map: all the cities move to new pixel positions, but the distances between them do not change. North might now point to the right instead of up, but Paris is still the same distance from London.
The reason this matters for quantization is that you can rotate the vectors into a coordinate system where they are easier to quantize (energy spread evenly, coordinates in a predictable range), quantize in that rotated system, and then the dot products you compute with the quantized vectors are the same as if you had quantized in the original system. You get the benefits of the rotation without changing what the model computes.
In TurboQuant, the rotation is in 128 dimensions instead of 2, and the orthogonal matrix is chosen randomly. But the same principle applies: lengths, distances, and dot products are all preserved.
Why rotate? Consider a KV cache vector where most of the information is concentrated in a few dimensions:
Before rotation: [5.2, 0.01, 0.03, 8.1, 0.02, 0.01, ...]
↑ ↑
These two dimensions carry almost all the energy.
The rest are near zero.
If you quantize this directly with, say, 4 levels per dimension, you waste 3 of the 4 levels on the near-zero dimensions (they are all roughly the same, so you do not need 4 levels to represent them). Meanwhile, the two important dimensions really need more than 4 levels.
After a random rotation, the energy gets spread evenly:
After rotation: [1.4, 1.2, 0.9, 1.3, 1.1, 1.0, ...]
All dimensions now carry similar energy.
4 levels per dimension is used efficiently everywhere.
This is the same idea as the Hadamard rotation in PolarQuant, but TurboQuant uses a random orthogonal matrix instead of a fixed Hadamard matrix. The difference matters for the theory. A fixed matrix like Hadamard works well in practice, but an adversary could construct a specific input vector that is already aligned with the Hadamard matrix in a way that the rotation does not help. A random matrix does not have this weakness: because the matrix is chosen randomly, no input vector can be “pre-aligned” with it. This is what allows TurboQuant to prove worst-case guarantees that hold for any input, not just typical inputs. The TurboQuant paper (Theorem 1) formalizes this.
The rotation also has a second benefit that is specific to high-dimensional spaces. In 2 or 3 dimensions, a random rotation can move energy around in unpredictable ways. But in 128 dimensions, a mathematical result called the concentration of measure phenomenon kicks in. It says that after a random rotation, every single coordinate of the rotated vector ends up close to the same value. Not approximately, not usually, but with high probability. The higher the dimension, the tighter this concentration.
The distribution each coordinate follows is called a Beta distribution. Unlike the Gaussian (bell curve), which stretches from negative infinity to positive infinity, the Beta distribution lives within a fixed bounded range (between 0 and 1, after scaling). In 128 dimensions, the Beta distribution is very narrow: most coordinates end up clustered tightly around a single predictable value.
Before rotation (128 dims): values all over the place
[5.2, 0.01, -3.1, 0.03, 8.1, -0.5, ...] range: -3.1 to 8.1
After random rotation (128 dims): values concentrated
[0.41, 0.38, 0.43, 0.39, 0.40, 0.42, ...] range: roughly 0.35 to 0.45
Each coordinate independently follows a Beta distribution
centered around ≈ 0.40 with very little spread.
This concentration is what makes the whole approach work. Because the distribution is known and narrow, you can design quantization levels that are perfectly matched to it. No levels are wasted on values that will never appear.
Before rotation: coordinate values can be anything
[-8.1, 0.01, 5.2, -0.3, ...] (unpredictable, wide range)
After rotation: each coordinate ≈ Beta distributed
[0.41, 0.38, 0.43, 0.39, ...] (predictable, narrow range)
Because this distribution is known in advance (it comes from the math of random rotations, not from the data), the optimal quantization levels for each coordinate can be computed once and reused forever. There is no codebook to learn, no Lloyd’s algorithm to run, no calibration data to collect. The quantizer is fully determined by two things: how many dimensions the vector has and how many bits you want to use per dimension.
This is what data-oblivious means: the quantization scheme is fixed before you see any data. A new token arrives, you rotate its key/value vector, quantize each coordinate using the precomputed levels, and you are done. No adaptation, no learning, no state to maintain. This is exactly what you need for the KV cache, where vectors arrive one token at a time during generation.
The paper proves that this approach achieves distortion within a factor of 2.7 of Shannon’s theoretical minimum. As we covered earlier, the fact that it can guarantee a constant factor bound at all is what matters: the distortion is predictable and bounded no matter what input it sees.
Stage 2: Fix the dot product error with QJL
Stage 1 does a good job of minimizing reconstruction error (the difference between the original vector and the quantized version). But reconstruction error is not what attention cares about. Attention computes the dot product between query and key vectors. It is possible for a quantizer to have low reconstruction error but still give bad dot product estimates.
Here is why. Suppose quantization consistently rounds values slightly upward. The reconstructed vector is close to the original (low MSE), but every dot product computed with it is slightly too high because both vectors got bumped up. This systematic shift is called bias.
Example of bias in dot products:
Original vectors: a = [1.0, 2.0] b = [3.0, 1.0]
True dot product: 1.0×3.0 + 2.0×1.0 = 5.0
Quantized (biased upward):
a' = [1.1, 2.1] b' = [3.1, 1.1]
Estimated dot product: 1.1×3.1 + 2.1×1.1 = 3.41 + 2.31 = 5.72
The MSE is small (each value is off by 0.1), but the dot product
estimate is 5.72 instead of 5.0. That is a 14% error, which
could shift which tokens get the highest attention scores.
To fix this, TurboQuant adds a correction step using QJL. First, it computes the residual: the difference between the original vector and the quantized version. The residual captures everything the quantizer got wrong.
Original (after rotation): v' = [0.41, 0.38, 0.43, 0.39, ...]
Quantized: q(v') = [0.40, 0.40, 0.45, 0.40, ...]
Residual: error = [0.01, -0.02, -0.02, -0.01, ...]
TurboQuant then applies the QJL transform to this residual. As we saw in the QJL section, this means: multiply by a random matrix, then keep only the sign of each result.
Residual: [0.01, -0.02, -0.02, -0.01, ...]
|
Multiply by random matrix R
|
Projected residual: [0.003, -0.015, 0.008, -0.012, ...]
|
Keep only the sign
|
Stored: [+1, -1, +1, -1, ...] (1 bit each, no metadata)
This costs just 1 extra bit per dimension and adds zero metadata overhead.
At attention time, the dot product estimate combines the quantized vectors and the QJL correction. The QJL correction cancels out the bias from the quantizer, producing an unbiased estimate of the true dot product.
TurboQuant full pipeline:
Input vector v (128 dimensions, FP16 = 16 bits per dim)
|
Multiply by random orthogonal matrix R
|
v' = Rv (each coordinate now Beta distributed, predictable range)
|
Quantize each coordinate using precomputed levels
|
q(v') stored in 3 bits per dimension
|
Compute residual: error = v' - q(v')
|
Apply QJL to residual → 1 sign bit per dimension
|
Total storage per dimension: 3 bits (quantized) + 1 bit (QJL) = 4 bits
Compression: 16 bits → 4 bits = 4x reduction
At attention time:
dot_product(query, key)
≈ dot_product(q(query'), q(key')) ← from quantized vectors
+ QJL_correction(residual) ← removes bias
The total cost per dimension is the quantization bits plus 1 bit for the QJL correction. At 3 bits of quantization plus 1 bit of QJL, that is 4 bits per dimension total, a 4x compression from FP16. At 2 bits of quantization plus 1 bit of QJL, that is 3 bits total, roughly a 5x compression.
Benchmark Results
The Google blog reports evaluations across standard long-context benchmarks (LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval) using open-source models (Gemma and Mistral), with additional results on Llama-3.1-8B-Instruct for the LongBench benchmark.
KV cache compression quality: TurboQuant quantizes the KV cache to 3 bits without requiring training or fine-tuning and without any compromise in model accuracy. The blog frames this as achieving “optimal scoring performance in terms of both dot product distortion and recall while simultaneously minimizing the KV memory footprint.”
Needle-in-haystack tasks: These tests check if a model can find one specific, tiny piece of information buried inside a massive amount of text. TurboQuant achieves perfect scores across all benchmarks while reducing the KV memory by a factor of at least 6x. PolarQuant is also nearly lossless on this task. If the KV cache loses too much precision, the model forgets information from earlier in the context and either makes something up or gives a wrong answer.
Runtime performance: The blog describes TurboQuant as “exceptionally efficient to implement” with “negligible runtime overhead.” 4-bit TurboQuant achieves up to 8x speedup in computing the attention scores over the 32-bit (FP32) unquantized baseline. The comparison is against FP32, not FP16 which is the more common precision used in production inference. The speedup relative to FP16 would be roughly half (4x), since FP16 is already 2x smaller than FP32.
Vector search: Beyond KV cache compression, TurboQuant was also evaluated on high-dimensional vector search using the GloVe dataset (200 dimensions). It achieves better recall ratios than existing methods (Product Quantization and RabbiQ), despite those baselines using data-dependent training while TurboQuant is data-oblivious.
The blog highlights Gemini as a major application for this work and notes that the impact extends to semantic search at Google’s scale.
Sources
- Google Research Blog: TurboQuant: Redefining AI efficiency with extreme compression (March 2026)
- Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal
- Lloyd, S. P. (1982). Least Squares Quantization in PCM. IEEE Transactions on Information Theory
- Linde, Buzo, Gray (1980). An Algorithm for Vector Quantizer Design. IEEE Transactions on Communications
- GPTQ: Frantar et al. (2022). Accurate Post-Training Quantization for Generative Pre-trained Transformers
- AWQ: Lin et al. (2023). Activation-aware Weight Quantization for LLM Compression and Acceleration
- SmoothQuant: Xiao et al. (2022). Accurate and Efficient Post-Training Quantization for Large Language Models
- QuIP: Chee et al. (2023). 2-Bit Quantization of Large Language Models With Guarantees
- QuIP#: Tseng et al. (2024). Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks
- AQLM: Egiazarian et al. (2024). Extreme Compression of Large Language Models via Additive Quantization
- QJL: Zandieh, Daliri, Han (2024). 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead
- KIVI: Liu et al. (2024). A Tuning-Free Asymmetric 2bit Quantization for KV Cache
- KVQuant: Hooper et al. (2024). Towards 10 Million Context Length LLM Inference with KV Cache Quantization
- GEAR: Kang et al. (2024). An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM
- PolarQuant: Han, Kacham, Karbasi, Mirrokni, Zandieh (2025). Quantizing KV Caches with Polar Transformation
- TurboQuant: Zandieh, Daliri, Hadian, Mirrokni (2025). Online Vector Quantization with Near-optimal Distortion Rate
- ECO: Nikdan et al. (2026). Quantized Training without Full-Precision Master Weights
]]>